
















Verbreitete SEO-Irrtümer #3: Wer mehr schreibt, gewinnt!
Nachdem ich in meinem letzten Artikel auf die Verwendung von Keywords in Texten eingegangen bin, möchte ich zum Abschluss dieser Beitragsreihe mit ein paar häufigen Missverständnissen aufräumen, die sich auf Webtexte im Allgemeinen beziehen. Der oben genannte Titel verrät nur einen Teil der Geschichte (der mir persönlich sehr wichtig ist); anfangen werde ich aber mit einer Erläuterung zur Textstrukturierung durch Überschriften.
Überschriften-Tags können flexibel genutzt werden
Die korrekte Zuweisung von Überschriften-Tags im HTML-Code wird oft als ein Optimierungshebel für die Suchmaschinenoptimierung angesehen. „Korrekt“ bedeutet in diesem Fall: Eine H1-Überschrift, danach dürfen H2-Überschriften folgen, erst danach dürfen H3 eingesetzt werden etc.. Bei diesen rigiden Vorgaben handelt es sich um den Irrglauben einiger SEOs – Google-Mitarbeiter haben in der Vergangenheit bekanntgegeben, dass auch mehrere H1-Tags auf einer Seite erlaubt sind und dass die Tags H2 bis H6 nicht in einer festen Reihenfolge verwendet werden müssen.
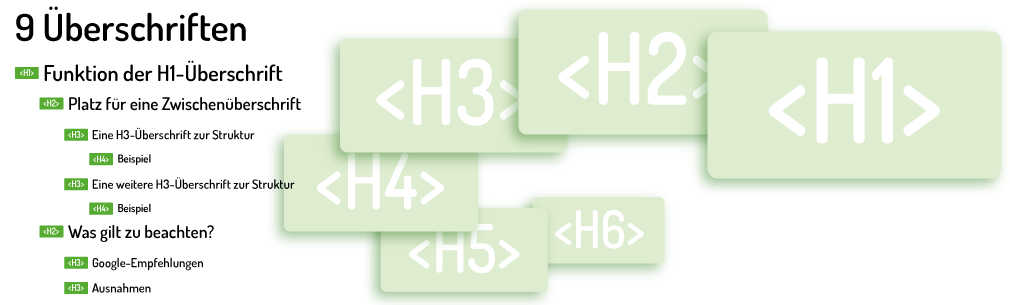
Diese gesamte Problematik bewegt sich natürlich im Prinzip auf technischer Ebene, hat allerdings direkte Auswirkungen auf den Text. Wer schon einmal eine längere wissenschaftliche Arbeit gelesen (oder zumindest überflogen) hat, wird eine gute Textstrukturierung mithilfe unterschiedlicher Überschriften zu schätzen wissen. Möchte man zum Beispiel eine Reihe „kleinerer“ thematischer Punkte zu Beginn eines Textes abarbeiten, kann man hierzu H3-Überschriften nutzen, bevor später größere Themenbereiche mit H2 überschrieben werden.
Und eine zweite H1-Überschrift kann in speziellen Fällen durchaus sinnvoll sein, wenn etwa auf einer Seite zwei in sich abgeschlossene Einzeltexte platziert werden.
Wer mehr schreibt, wird nicht zwangsläufig besser gefunden
„Content is King“ ist ein zentraler Leitspruch der Suchmaschinenoptimierung – und das zu Recht. Allerdings wird dieser Aussage allzu oft als Aufforderung verstanden, mehr und mehr Texte zu produzieren, wo es doch eigentlich um die Qualität der Inhalte geht. Wie Google-Repräsentanten im Laufe der Jahre immer wieder betont (und diverse Panda-Updates gezeigt) haben, sollte das Ziel einer Optimierung sein, Inhalte zu schaffen, die dem Suchenden dienlich sind.

Stattdessen findet man auf vielen Websites Dutzende von Landingpages, die denselben Inhalt ein ums andere Mal durchkauen. Hier wird meist die Strategie verfolgt, nur ein einzelnes Keyword pro Seite zu optimieren. Allerdings stellt sich dabei die Frage, ob es nicht effektiver wäre, mehrere Suchbegriffe auf einer Seite zu konsolidieren und somit das semantische Themenfeld des betreffenden Textes auszubauen.
Am anderen Ende des Spektrums stehen Websites, die mit zahlreichen Texten eine große Menge unterschiedlicher Gesichtspunkte gleichzeitig abzudecken versuchen. Das kann – insbesondere bei großen Webpräsenzen – sinnvoll und angebracht sein. Wenn sich jedoch eine kleine Homepage ohne klar definierten thematischen Fokus nach mehreren Richtungen gleichzeitig orientiert, wird die Suchmaschine Probleme haben, zu ergründen, was diese Website eigentlich sein will. Eine solche Seite werden Google und Co. kaum als hilfreiche Anlaufstelle für den Nutzer einordnen.
Duplicate Content ist kein alles verschlingendes SEO-Monster
Der letzte von mir betrachtete Mythos betrifft Duplicate Content. Erwähnt man diesen im Gespräch, verziehen die meisten SEOs unwillkürlich das Gesicht. DC hat den Ruf einer tödlichen Krankheit, die man um jeden Preis meiden sollte – oder den eines Monsters, das die eigenen Rankings verschlingt, wenn man ihm den Nährboden schafft (so wie das Krümelmonster gnadenlos sämtliche Kekse in Reichweite vertilgt). Sicherlich ist es für Suchmaschinen kein positives Signal, wenn die eigene Seite an mehreren Stellen identische Textinhalte aufweist – schließlich ist dies aus praktischer Sicht das Gegenteil von „Mehrwert“ für den User. Allerdings bedeutet DC nicht in allen Fällen gleich ein Todesurteil für die Suchmaschinenoptimierung.
Vielmehr versuchen Google und andere Suchplattformen, bei der Auswertung einer Website das relevanteste Ergebnis zu ermitteln. Weisen mehrere Unterseiten identische Textteile auf, werden diese im Normalfall einfach ignoriert; die Suchmaschine versucht dann, anhand der unterscheidenden Inhalte diejenige Seite zu finden, die am besten zur Suchanfrage passt. Gerade bei bestimmten Textpassagen – beispielsweise rechtlichen Informationen, die auf bestimmten Unterseiten zwangsläufig genannt werden müssen –, muss niemand mit einer Abwertung (oder sogar Abstrafung) rechnen. Zudem gibt es für Webmaster zahlreiche Möglichkeiten, die häufigsten Duplicate Content-Fehler zu beheben.
Gefährlich wird es ausschließlich dann, wenn die doppelten Inhalte den Eindruck einer Spamming-Maßnahme erwecken, um die Suchmaschinenplatzierung zu manipulieren. Wer also tatsächlich identische Texte auf seiner Website einstellt, in denen er lediglich einige Suchbegriffe durch Synonyme ersetzt, wird von Google und Co. völlig zu Recht aus dem Verkehr gezogen. Übrigens braucht ihr auch den Diebstahl der eigenen Texte nicht zu fürchten: Wenn ein fremder Website-Betreiber Inhalte von eurer Homepage kopiert, kann die Suchmaschine in aller Regel anhand des Einstellungszeitpunkts entscheiden, welcher Text das „Original“ ist.
Der Abschluss einer mythischen Reihe
Damit schließe ich meine Abhandlung textbezogener SEO-Mythen. Natürlich stellen die von mir beschriebenen Themen nur eine kleine Auswahl der vielfältigen Missverständnisse da, die im Bezug auf die Suchmaschinenoptimierung im Netz und in den Köpfen kursieren. Ich hoffe, ihr habt trotzdem etwas Interessantes erfahren oder die Anregung gewonnen, zu dem einen oder anderen Thema selbst etwas näher zu recherchieren – schließlich gibt es im Rahmen eines so komplexen Feldes wie SEO immer etwas Neues zu entdecken. Wenn ihr selbst weitere Fragen oder Anregungen habt, teilt mir diese gern in den Kommentaren mit!


{kind=link}